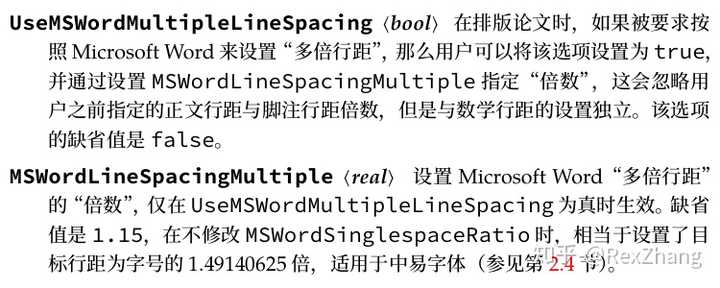
如何评价思源等宽(Source Han Mono,源ノ等幅)字族?

思源等宽(简体中文名)版本 1.000 于 2019 年 5 月 26 日正式发布,不久用户便表示有问题,随即更新的 1.001 于 5 月 30 日发布(见底部更新),与思源黑体、思源宋体一样,通过 SIL OFL 授权协议发布。
发行的字体版本仅有一种——Super OTC
与思源黑体、思源宋体多种下载版本不同,小林剑博士表示官方发行的思源等宽将仅仅含有 Super OTC(OpenType Collection)一种,即将全部字重、全部支持的语言、正体、斜体(新!)共 70 个字体打包成一个文件。官方不会发布思源等宽的「地区子集(Region-specific Subset)版本」或是「语言特定(Language-specific)版本」。
这就意味着从官方下载到的字体文件,安装到旧一点的操作系统上是用不了的(例如 Windows 8)。不过,既然思源等宽是开源的,用户完全可以使用源代码自己生成所需的字体文件。
字形设计方面
思源等宽是从四年前的 Source Han Code JP(源ノ角ゴシック Code)发展而来的,西文部分从 Source Code Pro 修改而来,汉字、假名部分则直接从思源黑体拿过来(半角假名、谚文需要适当修改)。思源等宽 1.000 与思源黑体 2.001 在字重、支持语言方面一致,但出于「编程字体」的考虑,思源黑体中一些用不到编程里的字形就没有收录,这为西文斜体腾出了空间。
- 七个字重(EL、L、N、R、M、B、H)
- 五种语言(日、韩、简中、繁中台湾、繁中香港)
- 西文部分有正体与斜体


字形设计上的评价,无需在此重复。
用来显示代码,对得齐吗?
严格来说,思源等宽是对不齐的。思源等宽的西文部分的水平距离设定为 667(包括西文空格),而汉字部分的水平距离设定为 1000,也就是说,原设计者服部正貴的初衷是「两个汉字对齐三个字母」。稍微一算就知道 667×3 > 1000×2,因此严格来说是不可能对齐的。

思源等宽无意解决对不齐的问题,算是一大遗憾。
个人使用体验
除了源代码抄录,我还会将代码片段插入到正文中去。因为应用的场合,我其实不太欣赏 Source Code Pro 的设计。身边的程序员朋友都评价 Source Code Pro 用起来不错,但我用在正文排版的时候,总感觉 Source Code Pro 非常肥硕。如果水平距离 600 的 Source Code Pro 看起来都臃肿了,那么可以感受一下思源等宽 667 的效果:

这一现象外国网友也曾经在 GitHub 上提过(Create a more condensed version of the font · Issue #12 · adobe-fonts/source-code-pro),根本原因是 Source Code Pro 本身的小写字高(x-height)比较小,导致字母比例看起来比较肥。用在长篇代码抄录或许很好,但是用在正文引用代码片段的效果就不佳。


目前看来,两个汉字配三个字母在实际效果上其实并不好(正文环境。另,官方的 ReadMe 文档看着心累……),更何况还没有完美对齐。相比之下,窄体系列(西文水平距离 500)的 M+(开源免费)、Iosevka(开源免费)、PragmataPro(商业字体)都是很好的替代,一个汉字配两个字母,绝对不会对不齐。
话说回来,如果可以接受两个汉字配三个字母,那么也应该可以接受三个汉字配五个字母吧。这样的话,大多数西文等宽字体都可以用了(水平距离一般都是 600),像 Inconsolata(开源免费)、Fira Code(开源免费)、Triplicate(商业字体)这些。
有什么值得学习的技术呢?
思源等宽的字符一共有三类水平距离:0、667 与 1000,要将半角假名(水平距离 500)与谚文音节(水平距离 920)纳入其中,就需要对它们进行变换,普通人的办法「把字形直接水平拉伸不就好了嘛」在字型设计师们看来堪比「犯罪」。所幸的是,专业造字软件有「水平拉伸字形但能保持竖划不变粗」的变换功能,这就为「拉伸半角假名到 667、拉伸谚文音节到 1000」提供了可能。小林剑博士称这种方法为「anisotropic techniques(各向异性技巧?)」。
在我看来,通过这种机械的方法将谚文伸展 108.7% 还可以接受,但是半角假名伸展 133.4% 之后就显得比例失调了。或许,这个技术最大的应用是创造数学字体:仔细观察 LaTeX 默认的文本斜体+数学斜体、或者是对比商业字体 Times New Roman(文本斜体)+ MathTime Pro 2(数学斜体),都可以发现数学斜体不是文本斜体的简单复制,而是比文本稍宽的字体,水平拉伸在 105% 左右。数学字体的开源项目可以利用这个技术绘制 Mathematical Alphanumeric Symbols 区块的字形(当然,数学字体的 side bearing 与 kerning 都是需要另外调整的)。
版本 1.001 有什么更新?
- 由于 hinting 参数设置不当,导致圆的字形栅格化后看起来太高,这个问题在四天后的 1.001 中得到修复。
- 西塚涼子亲自修复半角假名比例失调的问题。



